安全扫描自动化检测平台建设(Web黑盒中)
注:本文为“小米安全中心”原创,转载请联系“小米安全中心”
安全自动化扫描平台建设——扫描平台设计
1.指纹识别
指纹识别是扫描器的雷达卫星,能在真正需要的时候准确命中目标,指纹识别不仅仅包括Web服务器,还包括设备资产的指纹,一个IP对应的是一台服务器还是一台个人机还是一台打印机?这意味着安全域是不同的,攻下他需要的武器更是不一样。
Web框架指纹扫描在大型甲方公司其实需求并不是非常迫切,成型的框架比如WordPress,Drupal,Joomla!,Discuz! 等使用并不多,多是官方论坛,某个部门的对外Blog之类,多数是进行了二次开发,这里以WordPress举例指纹扫描:
- 使用Whatweb集群进行Web指纹扫描,发现公司某站点使用了WordPress。
- WPscan继续进行扫描,发现该站点WordPress版本号,主题,插件。插件版本,后台,存在admin用户
- 在漏洞库进行查询,发现某插件版本过低,存在SQLi漏洞
- 根据漏洞情况,产出安全报警,包括该网站负责人,IP,域名,所在IDC,漏洞详情
- 安全运维同学跟进修复漏洞,如果发现入侵事件,由安全管理同学进行安全事件管理流程。
其实我们更加关心的是开发框架,比如Status2,Laravel,自研开发框架等,由于使用面广,业务线分布密集,出现安全事故的话会导致非常严重的后果,所以会采用Whatweb服务集群或者自研的方式进行扫描,并且该类型指纹只有在网站进行大规模的重构上线的时候会有变化,其他时间不会有频繁的变动,所以在非漏洞爆发阶段,这类指纹扫描间隔可以非常大,不会对服务器造成额外的压力。
大型互联网公司的网络边界越来越模糊,很多服务器存在多种漏洞,并且无限制的连接IDC/办公网,一旦被攻破就是个绝佳的跳板。这种情况越是大公司越是明显,安全的木桶效应。
IP相关信息运维部门会比较了解,部门间进行合作可以拿到全IP对应的相关信息,但是,依然不能保证这份IP就是全IP,这就要从流量镜像入手了,从流量中发现未在IP库中的机器,只要有网络请求,就不愁发现不了。进而扩充安全资产IP库,但是实施的时候会发现由于网络划分的问题其实也并不能全部发现IP。
IP资产信息包括OS,设备信息,端口,服务,这能让你知道这个IP背后到底是交换机还是打印机,上面都跑了什么服务,这些服务的版本(如果有),对应存在的漏洞就能直接进行扫描,可以在漏洞发现的第一时间进行全资产扫描,精准的发现存在漏洞的资产范围,所属部门,并且可以非常快的进行漏洞修复流程。每一次的漏洞爆发都是和攻击者的一次赛跑,也许,攻击者手中也有一份类似的指纹库。
架构上主要使用Nmap集群服务,Nmap的CPE数据持续更新,要保证我们的设备可以被正确的识别。
由于设备上的服务可能会不断的新增/变更,不能保证每一次的新增/变更都是安全的,所以采用轮询的扫描机制,持续更新IP资产库,尽性能的可能,保证这份IP资产库保持最新。
讲个由此发生的成功入侵的故事:某公司给员工提供了开发机,原本这类开发机的默认安全规则是不对外网开放的,但是这台开发机上个使用者申请开了外网权限,回收的时候出现BUG,并没有取消外网权限,然而新的使用者对此并不知情。
新的开发同学使用了Redis数据库,开放了外连,并且没有密码。被攻击者扫描到以后获取了服务器权限,偏偏服务器上有开发中的代码(这是必然会有的),审计发现了线上服务器的安全漏洞,并得到了其他内网服务的用户名密码,这里面包括了内网用户密码、数据库用户名密码。结果造成了非常严重的安全事件。
由此可见,员工的安全意识完全不可以信任,依然要使用技术手段进行安全管理与识别。
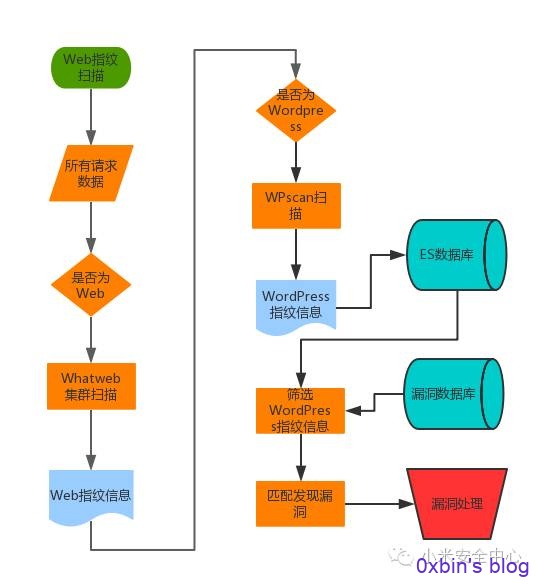
图1 指纹识别流程
2.资产管理
前面说了很多的资产库的问题,引出了甲方安全最头痛的事:资产管理。各位SRC的同学应该深深的明白优秀的资产管理到底有多重要,漏洞审计完了,找不到接口人,有的甚至各个部门都不认,安全工单发不出,愁死人。
资格管理分为:
- 数据资产
- 设备资产
数据资产可以通过DNS,流量,爬虫,配置管理等部门获取,这个可以比较主动的通过技术的方法拿。
而设备资产除了找相关部门获取以外,技术方面只能通过流量和扫描的方式进行获取,然而比较麻烦的是,由于网络的原因,有可能某些机器的流量是不通过你的交换机或者无法网络不可达,所以技术方式并不能发现所有的设备,导致数据缺失。
业务部门是安全的第一责任人,在安全部门输出安全能力的情况下,可以推动业务部门来推动资产管理和其他安全事项。这样多管齐下,尽可能的完善安全的资产管理体系,方法和思路很多,在此不再赘述。
当然,资产管理不可能做到面面俱到,每台服务器,每个业务100%都能准确的找到负责人,所以这种情况下安全风险必须知会到合适的层级,并得到相应合理的对待。
3.数据管理
从各个数据源传输过来的数据要经过一系列的处理,才能最后进入我们的资产库,供各项扫描器调用。
首先URL数据是最为庞大的,未经去重的URL数据(GET请求和部分POST请求)数据,量级极为恐怖,如果不经过处理直接入库,会对后端扫描器和业务方造成极大的压力,所以URL入库前的处理,是扫描器开发的一个难点。
主要思路是数据清洗后再进行相应的预处理,这是大数据处理的基础办法:
(1)URL清洗,首先将完全不需要URL数据进行清洗,包括图片,友好404页面等
(2)URL规范化(注1)
(3)URL全量去重,目前两种简单的实现方法,Redis Hash 或者采用布隆过滤器(注2)
(4)URL分类:分为接口URL类和路径重写类
- 接口URL类去重:Hash去重
- 路径重写类去重:有几种实现方法:
- 动态规则法:对URL进行规则发现,比如:http://list.mi.com/174http://list.mi.com/177
生成规则为:http://list.mi.com/[0-9]+
对其后所有http://list.mi.com/ 路径深度为2的URL进行正则匹配,成功则认为重复,不成功则认为不重复,进入数据库,并生成新的匹配规则。
- 机器学习:使用聚类算法中的朴素贝叶斯算法
- 我们正在使用全新的算法,在全量测试中表现不错,唯一的缺点是在某些URL效果不佳,但是依然处于可以接受的范围
URL的完全去重在技术上非常复杂和困难,完全没必要用百度或者谷歌的爬虫策略要求自己,只要在可接受范围内,就算是只进行全量去重也没关系。
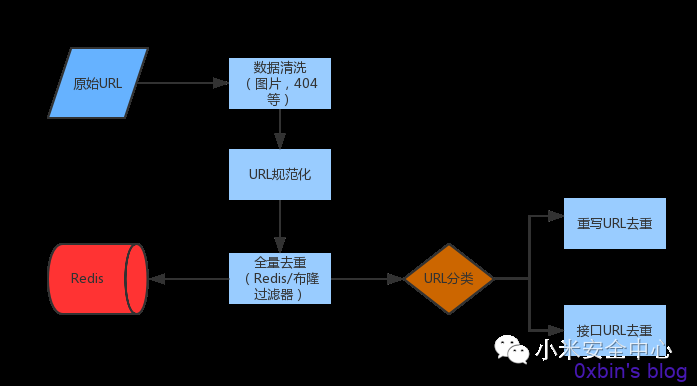
图2 URL数据去重的流程
原文链接:https://sec.xiaomi.com/article/10